Dynamic programming
In mathematics and computer science, dynamic programming is a method of solving complex problems by breaking them down into simpler steps. It is applicable to problems that exhibit the properties of overlapping subproblems which are only slightly smaller[1] and optimal substructure (described below). When applicable, the method takes much less time than naive methods.
Top-down dynamic programming simply means storing the results of certain calculations, which are then re-used later because the same calculation is a sub-problem in a larger calculation. Bottom-up dynamic programming involves formulating a complex calculation as a recursive series of simpler calculations.
Contents |
History
The term dynamic programming was originally used in the 1940s by Richard Bellman to describe the process of solving problems where one needs to find the best decisions one after another. By 1953, he had refined this to the modern meaning, which refers specifically to nesting smaller decision problems inside larger decisions,[2] and the field was thereafter recognized by the IEEE as a systems analysis and engineering topic. Bellman's contribution is remembered in the name of the Bellman equation, a central result of dynamic programming which restates an optimization problem in recursive form.
The word dynamic was chosen by Bellman because it sounded impressive, not because it described how the method worked.[3] The word programming referred to the use of the method to find an optimal program, in the sense of a military schedule for training or logistics. This usage is the same as that in the phrases linear programming and mathematical programming, a synonym for optimization.[4]
Overview

Dynamic programming is both a mathematical optimization method, and a computer programming method. In both contexts, it refers to simplifying a complicated problem by breaking it down into simpler subproblems in a recursive manner. While some decision problems cannot be taken apart this way, decisions that span several points in time do often break apart recursively; Bellman called this the "Principle of Optimality". Likewise, in computer science, a problem which can be broken down recursively is said to have optimal substructure.
If subproblems can be nested recursively inside larger problems, so that dynamic programming methods are applicable, then there is a relation between the value of the larger problem and the values of the subproblems.[5] In the optimization literature this relationship is called the Bellman equation.
Dynamic programming in mathematical optimization
In terms of mathematical optimization, dynamic programming usually refers to a simplification of a decision by breaking it down into a sequence of decision steps over time. This is done by defining a sequence of value functions V1 , V2 , ... Vn , with an argument y representing the state of the system at times i from 1 to n. The definition of Vn(y) is the value obtained in state y at the last time n. The values Vi at earlier times i=n-1,n-2,...,2,1 can be found by working backwards, using a recursive relationship called the Bellman equation. For i=2,...n, Vi -1 at any state y is calculated from Vi by maximizing a simple function (usually the sum) of the gain from decision i-1 and the function Vi at the new state of the system if this decision is made. Since Vi has already been calculated for the needed states, the above operation yields Vi -1 for those states. Finally, V1 at the initial state of the system is the value of the optimal solution. The optimal values of the decision variables can be recovered, one by one, by tracking back the calculations already performed.
Dynamic programming in computer programming
There are two key attributes that a problem must have in order for dynamic programming to be applicable: optimal substructure and overlapping subproblems which are only slightly smaller. When the overlapping problems are, say, half the size of the original problem the strategy is called "divide and conquer" rather than "dynamic programming". This is why mergesort, and quicksort, and finding all matches of a regular expression are not classified as dynamic programming problems.
Optimal substructure means that the solution to a given optimization problem can be obtained by the combination of optimal solutions to its subproblems. Consequently, the first step towards devising a dynamic programming solution is to check whether the problem exhibits such optimal substructure. Such optimal substructures are usually described by means of recursion. For example, given a graph G=(V,E), the shortest path p from a vertex u to a vertex v exhibits optimal substructure: take any intermediate vertex w on this shortest path p. If p is truly the shortest path, then the path p1 from u to w and p2 from w to v are indeed the shortest paths between the corresponding vertices (by the simple cut-and-paste argument described in CLRS). Hence, one can easily formulate the solution for finding shortest paths in a recursive manner, which is what the Bellman-Ford algorithm does.
Overlapping subproblems means that the space of subproblems must be small, that is, any recursive algorithm solving the problem should solve the same subproblems over and over, rather than generating new subproblems. For example, consider the recursive formulation for generating the Fibonacci series: Fi = Fi-1 + Fi-2, with base case F1=F2=1. Then F43 = F42 + F41, and F42 = F41 + F40. Now F41 is being solved in the recursive subtrees of both F43 as well as F42. Even though the total number of subproblems is actually small (only 43 of them), we end up solving the same problems over and over if we adopt a naive recursive solution such as this. Dynamic programming takes account of this fact and solves each subproblem only once. Note that the subproblems must be only 'slightly' smaller (typically taken to mean a constant additive factor) than the larger problem; when they are a multiplicative factor smaller the problem is no longer classified as dynamic programming (otherwise mergesort and quicksort would be dynamic programming problems).

This can be achieved in either of two ways:
- Top-down approach: This is the direct fall-out of the recursive formulation of any problem. If the solution to any problem can be formulated recursively using the solution to its subproblems, and if its subproblems are overlapping, then one can easily memoize or store the solutions to the subproblems in a table. Whenever we attempt to solve a new subproblem, we first check the table to see if it is already solved. If a solution has been recorded, we can use it directly, otherwise we solve the subproblem and add its solution to the table.
- Bottom-up approach: This is the more interesting case. Once we formulate the solution to a problem recursively as in terms of its subproblems, we can try reformulating the problem in a bottom-up fashion: try solving the subproblems first and use their solutions to build-on and arrive at solutions to bigger subproblems. This is also usually done in a tabular form by iteratively generating solutions to bigger and bigger subproblems by using the solutions to small subproblems. For example, if we already know the values of F41 and F40, we can directly calculate the value of F42.
Some programming languages can automatically memoize the result of a function call with a particular set of arguments, in order to speed up call-by-name evaluation (this mechanism is referred to as call-by-need). Some languages make it possible portably (e.g. Scheme, Common Lisp or Perl), some need special extensions (e.g. C++, see [6]). Some languages have automatic memoization built in such as tabled Prolog. In any case, this is only possible for a referentially transparent function.
Example: mathematical optimization
Optimal consumption and saving
A mathematical optimization problem that is often used in teaching dynamic programming to economists (because it can be solved by hand[7]) concerns a consumer who lives over the periods 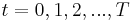 and must decide how much to consume and how much to save in each period.
and must decide how much to consume and how much to save in each period.
Let 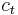 be consumption in period
be consumption in period 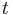 , and assume consumption yields utility
, and assume consumption yields utility 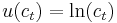 as long as the consumer lives. Assume the consumer is impatient, so that he discounts future utility by a factor
as long as the consumer lives. Assume the consumer is impatient, so that he discounts future utility by a factor  each period, where
each period, where  . Let
. Let 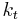 be capital in period . Assume initial capital is a given amount
be capital in period . Assume initial capital is a given amount 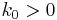 , and suppose that this period's capital and consumption determine next period's capital as
, and suppose that this period's capital and consumption determine next period's capital as 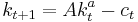 , where
, where  is a positive constant and
is a positive constant and 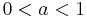 . Assume capital cannot be negative. Then the consumer's decision problem can be written as follows:
. Assume capital cannot be negative. Then the consumer's decision problem can be written as follows:
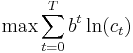 subject to
subject to  for all
for all
Written this way, the problem looks complicated, because it involves solving for all the choice variables 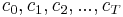 and
and 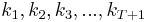 simultaneously. (Note that
simultaneously. (Note that 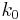 is not a choice variable—the consumer's initial capital is taken as given.)
is not a choice variable—the consumer's initial capital is taken as given.)
The dynamic programming approach to solving this problem involves breaking it apart into a sequence of smaller decisions. To do so, we define a sequence of value functions 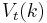 , for
, for 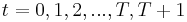 which represent the value of having any amount of capital
which represent the value of having any amount of capital 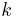 at each time . Note that
at each time . Note that 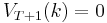 , that is, there is (by assumption) no utility from having capital after death.
, that is, there is (by assumption) no utility from having capital after death.
The value of any quantity of capital at any previous time can be calculated by backward induction using the Bellman equation. In this problem, for each , the Bellman equation is
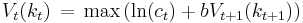 subject to
subject to
This problem is much simpler than the one we wrote down before, because it involves only two decision variables, and 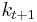 . Intuitively, instead of choosing his whole lifetime plan at birth, the consumer can take things one step at a time. At time , his current capital is given, and he only needs to choose current consumption and saving .
. Intuitively, instead of choosing his whole lifetime plan at birth, the consumer can take things one step at a time. At time , his current capital is given, and he only needs to choose current consumption and saving .
To actually solve this problem, we work backwards. For simplicity, the current level of capital is denoted as . 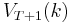 is already known, so using the Bellman equation once we can calculate
is already known, so using the Bellman equation once we can calculate 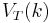 , and so on until we get to
, and so on until we get to  , which is the value of the initial decision problem for the whole lifetime. In other words, once we know
, which is the value of the initial decision problem for the whole lifetime. In other words, once we know  , we can calculate
, we can calculate  , which is the maximum of
, which is the maximum of 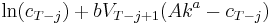 , where
, where 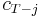 is the variable and
is the variable and 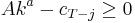 . It can be shown that the value function at time
. It can be shown that the value function at time 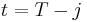 is
is
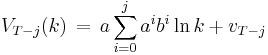
where each 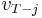 is a constant, and the optimal amount to consume at time is
is a constant, and the optimal amount to consume at time is
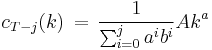
which can be simplified to
 , and
, and 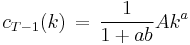 , and
, and 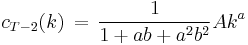 , etc.
, etc.
We see that it is optimal to consume a larger fraction of current wealth as one gets older, finally consuming all current wealth in period  , the last period of life.
, the last period of life.
Examples: Computer algorithms
Fibonacci sequence
Here is a naive implementation of a function finding the nth member of the Fibonacci sequence, based directly on the mathematical definition:
function fib(n)
if n = 0 return 0
if n = 1 return 1
return fib(n − 1) + fib(n − 2)
Notice that if we call, say, fib(5), we produce a call tree that calls the function on the same value many different times:
fib(5)fib(4) + fib(3)(fib(3) + fib(2)) + (fib(2) + fib(1))((fib(2) + fib(1)) + (fib(1) + fib(0))) + ((fib(1) + fib(0)) + fib(1))(((fib(1) + fib(0)) + fib(1)) + (fib(1) + fib(0))) + ((fib(1) + fib(0)) + fib(1))
In particular, fib(2) was calculated three times from scratch. In larger examples, many more values of fib, or subproblems, are recalculated, leading to an exponential time algorithm.
Now, suppose we have a simple map object, m, which maps each value of fib that has already been calculated to its result, and we modify our function to use it and update it. The resulting function requires only O(n) time instead of exponential time:
var m := map(0 → 0, 1 → 1)
function fib(n)
if map m does not contain key n
m[n] := fib(n − 1) + fib(n − 2)
return m[n]
This technique of saving values that have already been calculated is called memoization; this is the top-down approach, since we first break the problem into subproblems and then calculate and store values.
In the bottom-up approach we calculate the smaller values of fib first, then build larger values from them. This method also uses O(n) time since it contains a loop that repeats n − 1 times, however it only takes constant (O(1)) space, in contrast to the top-down approach which requires O(n) space to store the map.
function fib(n)
var previousFib := 0, currentFib := 1
if n = 0
return 0
else if n = 1
return 1
repeat n − 1 times
var newFib := previousFib + currentFib
previousFib := currentFib
currentFib := newFib
return currentFib
In both these examples, we only calculate fib(2) one time, and then use it to calculate both fib(4) and fib(3), instead of computing it every time either of them is evaluated.
A type of balanced 0-1 matrix
Consider the problem of assigning values, either zero or one, to the positions of an n × n matrix, n even, so that each row and each column contains exactly n / 2 zeros and n / 2 ones. For example, when n = 4, three possible solutions are

We ask how many different assignments there are for a given 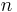 . There are at least three possible approaches: brute force, backtracking, and dynamic programming. Brute force consists of checking all assignments of zeros and ones and counting those that have balanced rows and columns (
. There are at least three possible approaches: brute force, backtracking, and dynamic programming. Brute force consists of checking all assignments of zeros and ones and counting those that have balanced rows and columns (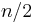 zeros and ones). As there are
zeros and ones). As there are  possible assignments, this strategy is not practical except maybe up to
possible assignments, this strategy is not practical except maybe up to  . Backtracking for this problem consists of choosing some order of the matrix elements and recursively placing ones or zeros, while checking that in every row and column the number of elements that have not been assigned plus the number of ones or zeros are both at least n / 2. While more sophisticated than brute force, this approach will visit every solution once, making it impractical for n larger than six, since the number of solutions is already 116963796250 for n = 8, as we shall see. Dynamic programming makes it possible to count the number of solutions without visiting them all.
. Backtracking for this problem consists of choosing some order of the matrix elements and recursively placing ones or zeros, while checking that in every row and column the number of elements that have not been assigned plus the number of ones or zeros are both at least n / 2. While more sophisticated than brute force, this approach will visit every solution once, making it impractical for n larger than six, since the number of solutions is already 116963796250 for n = 8, as we shall see. Dynamic programming makes it possible to count the number of solutions without visiting them all.
We consider k × n boards, where 1 ≤ k ≤ n, whose rows contain zeros and ones. The function f to which memoization is applied maps vectors of n pairs of integers to the number of admissible boards (solutions). There is one pair for each column and its two components indicate respectively the number of ones and zeros that have yet to be placed in that column. We seek the value of 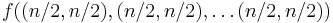 ( arguments or one vector of elements). The process of subproblem creation involves iterating over every one of
( arguments or one vector of elements). The process of subproblem creation involves iterating over every one of 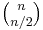 possible assignments for the top row of the board, and going through every column, subtracting one from the appropriate element of the pair for that column, depending on whether the assignment for the top row contained a zero or a one at that position. If any one of the results is negative, then the assignment is invalid and does not contribute to the set of solutions (recursion stops). Otherwise, we have an assignment for the top row of the k × n board and recursively compute the number of solutions to the remaining (k - 1) × n board, adding the numbers of solutions for every admissible assignment of the top row and returning the sum, which is being memoized. The base case is the trivial subproblem, which occurs for a 1 × n board. The number of solutions for this board is either zero or one, depending on whether the vector is a permutation of n / 2
possible assignments for the top row of the board, and going through every column, subtracting one from the appropriate element of the pair for that column, depending on whether the assignment for the top row contained a zero or a one at that position. If any one of the results is negative, then the assignment is invalid and does not contribute to the set of solutions (recursion stops). Otherwise, we have an assignment for the top row of the k × n board and recursively compute the number of solutions to the remaining (k - 1) × n board, adding the numbers of solutions for every admissible assignment of the top row and returning the sum, which is being memoized. The base case is the trivial subproblem, which occurs for a 1 × n board. The number of solutions for this board is either zero or one, depending on whether the vector is a permutation of n / 2 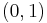 and n / 2
and n / 2 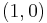 pairs or not.
pairs or not.
For example, in the two boards shown above the sequences of vectors would be
((2, 2) (2, 2) (2, 2) (2, 2)) ((2, 2) (2, 2) (2, 2) (2, 2)) k = 4 0 1 0 1 0 0 1 1 ((1, 2) (2, 1) (1, 2) (2, 1)) ((1, 2) (1, 2) (2, 1) (2, 1)) k = 3 1 0 1 0 0 0 1 1 ((1, 1) (1, 1) (1, 1) (1, 1)) ((0, 2) (0, 2) (2, 0) (2, 0)) k = 2 0 1 0 1 1 1 0 0 ((0, 1) (1, 0) (0, 1) (1, 0)) ((0, 1) (0, 1) (1, 0) (1, 0)) k = 1 1 0 1 0 1 1 0 0 ((0, 0) (0, 0) (0, 0) (0, 0)) ((0, 0) (0, 0), (0, 0) (0, 0))
The number of solutions (sequence A058527 in OEIS) is
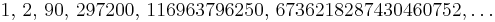
Links to the Perl source of the backtracking approach, as well as a MAPLE and a C implementation of the dynamic programming approach may be found among the external links.
Checkerboard
Consider a checkerboard with n × n squares and a cost-function c(i, j) which returns a cost associated with square i,j (i being the row, j being the column). For instance (on a 5 × 5 checkerboard),
| 5 | 6 | 7 | 4 | 7 | 8 |
|---|---|---|---|---|---|
| 4 | 7 | 6 | 1 | 1 | 4 |
| 3 | 3 | 5 | 7 | 8 | 2 |
| 2 | - | 6 | 7 | 0 | - |
| 1 | - | - | 5* | - | - |
| 1 | 2 | 3 | 4 | 5 |
Thus c(1, 3) = 5
Let us say you had a checker that could start at any square on the first rank (i.e., row) and you wanted to know the shortest path (sum of the costs of the visited squares are at a minimum) to get to the last rank, assuming the checker could move only diagonally left forward, diagonally right forward, or straight forward. That is, a checker on (1,3) can move to (2,2), (2,3) or (2,4).
| 5 | |||||
|---|---|---|---|---|---|
| 4 | |||||
| 3 | |||||
| 2 | x | x | x | ||
| 1 | o | ||||
| 1 | 2 | 3 | 4 | 5 |
This problem exhibits optimal substructure. That is, the solution to the entire problem relies on solutions to subproblems. Let us define a function q(i, j) as
- q(i, j) = the minimum cost to reach square (i, j)
If we can find the values of this function for all the squares at rank n, we pick the minimum and follow that path backwards to get the shortest path.
Note that q(i, j) is equal to the minimum cost to get to any of the three squares below it (since those are the only squares that can reach it) plus c(i, j). For instance:
| 5 | |||||
|---|---|---|---|---|---|
| 4 | A | ||||
| 3 | B | C | D | ||
| 2 | |||||
| 1 | |||||
| 1 | 2 | 3 | 4 | 5 |
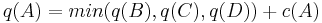
Now, let us define q(i, j) in somewhat more general terms:
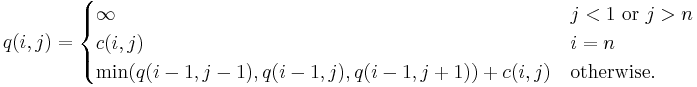
The first line of this equation is there to make the recursive property simpler (when dealing with the edges, so we need only one recursion). The second line says what happens in the last rank, to provide a base case. The third line, the recursion, is the important part. It is similar to the A,B,C,D example. From this definition we can make a straightforward recursive code for q(i, j). In the following pseudocode, n is the size of the board, c(i, j) is the cost-function, and min() returns the minimum of a number of values:
function minCost(i, j)
if j < 1 or j > n
return infinity
else if i = n
return c(i, j)
else
return min( minCost(i+1, j-1), minCost(i+1, j), minCost(i+1, j+1) ) + c(i, j)
It should be noted that this function only computes the path-cost, not the actual path. We will get to the path soon. This, like the Fibonacci-numbers example, is horribly slow since it spends mountains of time recomputing the same shortest paths over and over. However, we can compute it much faster in a bottom-up fashion if we store path-costs in a two-dimensional array q[i, j] rather than using a function. This avoids recomputation; before computing the cost of a path, we check the array q[i, j] to see if the path cost is already there.
We also need to know what the actual shortest path is. To do this, we use another array p[i, j], a predecessor array. This array implicitly stores the path to any square s by storing the previous node on the shortest path to s, i.e. the predecessor. To reconstruct the path, we lookup the predecessor of s, then the predecessor of that square, then the predecessor of that square, and so on, until we reach the starting square. Consider the following code:
function computeShortestPathArrays()
for x from 1 to n
q[1, x] := c(1, x)
for y from 1 to n
q[y, 0] := infinity
q[y, n + 1] := infinity
for y from 2 to n
for x from 1 to n
m := min(q[y-1, x-1], q[y-1, x], q[y-1, x+1])
q[y, x] := m + c(y, x)
if m = q[y-1, x-1]
p[y, x] := -1
else if m = q[y-1, x]
p[y, x] := 0
else
p[y, x] := 1
Now the rest is a simple matter of finding the minimum and printing it.
function computeShortestPath()
computeShortestPathArrays()
minIndex := 1
min := q[n, 1]
for i from 2 to n
if q[n, i] < min
minIndex := i
min := q[n, i]
printPath(n, minIndex)
function printPath(y, x)
print(x)
print("<-")
if y = 2
print(x + p[y, x])
else
printPath(y-1, x + p[y, x])
Sequence alignment
In genetics, sequence alignment is an important application where dynamic programming is essential.[3] Typically, the problem consists of transforming one sequence into another using edit operations that replace, insert, or remove an element. Each operation has an associated cost, and the goal is to find the sequence of edits with the lowest total cost.
The problem can be stated naturally as a recursion, a sequence A is optimally edited into a sequence B by either:
- inserting the first character of B, and performing an optimal alignment of A and the tail of B
- deleting the first character of A, and performing the optimal alignment of the tail of A and B
- replacing the first character of A with the first character of B, and performing optimal alignments of the tails of A and B.
The partial alignments can be tabulated in a matrix, where cell (i,j) contains the cost of the optimal alignment of A[1..i] to B[1..j]. The cost in cell (i,j) can be calculated by adding the cost of the relevant operations to the cost of its neighboring cells, and selecting the optimum.
Different variants exist, see Smith-Waterman and Needleman-Wunsch.
Algorithms that use dynamic programming
- Backward induction as a solution method for finite-horizon discrete-time dynamic optimization problems
- Method of undetermined coefficients can be used to solve the Bellman equation in infinite-horizon, discrete-time, discounted, time-invariant dynamic optimization problems
- Many string algorithms including longest common subsequence, longest increasing subsequence, longest common substring, Levenshtein distance (edit distance).
- Many algorithmic problems on graphs can be solved efficiently for graphs of bounded treewidth or bounded clique-width by using dynamic programming on a tree decomposition of the graph.
- The Cocke-Younger-Kasami (CYK) algorithm which determines whether and how a given string can be generated by a given context-free grammar
- The use of transposition tables and refutation tables in computer chess
- The Viterbi algorithm (used for hidden Markov models)
- The Earley algorithm (a type of chart parser)
- The Needleman-Wunsch and other algorithms used in bioinformatics, including sequence alignment, structural alignment, RNA structure prediction.
- Floyd's All-Pairs shortest path algorithm
- Optimizing the order for chain matrix multiplication
- Pseudopolynomial time algorithms for the Subset Sum and Knapsack and Partition problem Problems
- The dynamic time warping algorithm for computing the global distance between two time series
- The Selinger (a.k.a. System R) algorithm for relational database query optimization
- De Boor algorithm for evaluating B-spline curves
- Duckworth-Lewis method for resolving the problem when games of cricket are interrupted
- The Value Iteration method for solving Markov decision processes
- Some graphic image edge following selection methods such as the "magnet" selection tool in Photoshop
- Some methods for solving interval scheduling problems
- Some methods for solving word wrap problems
- Some methods for solving the travelling salesman problem, either exactly (in exponential time) or approximately (e.g. via the bitonic tour)
- Recursive least squares method
- Beat tracking in Music Information Retrieval.
- Adaptive Critic training strategy for artificial neural networks
- Stereo algorithms for solving the Correspondence problem used in stereo vision.
- Seam carving (content aware image resizing)
- The Bellman-Ford algorithm for finding the shortest distance in a graph.
- Some approximate solution methods for the linear search problem.
See also
- Bellman equation
- Divide and conquer algorithm
- Greedy algorithm
- Markov Decision Process
- Stochastic programming
References
- ↑ S. Dasgupta, C.H. Papadimitriou, and U.V. Vazirani, 'Algorithms', p173, available at http://www.cs.berkeley.edu/~vazirani/algorithms.html
- ↑ http://www.wu-wien.ac.at/usr/h99c/h9951826/bellman_dynprog.pdf
- ↑ 3.0 3.1 Eddy, S. R., What is dynamic programming?, Nature Biotechnology, 22, 909-910 (2004).
- ↑ Nocedal, J.; Wright, S. J.: Numerical Optimization, page 9, Springer, 2006..
- ↑ Cormen, T. H.; Leiserson, C. E.; Rivest, R. L.; Stein, C. (2001), Introduction to Algorithms (2nd ed.), MIT Press & McGraw-Hill, ISBN 0-262-03293-7 . pp. 327–8.
- ↑ http://www.apl.jhu.edu/~paulmac/c++-memoization.html
- ↑ Stokey et al., 1989, Chap. 1
Further reading
- Adda, Jerome; Cooper, Russell (2003), Dynamic Economics, MIT Press, http://www.eco.utexas.edu/~cooper/dynprog/dynprog1.html. An accessible introduction to dynamic programming in economics. The link contains sample programs.
- Bellman, Richard (1957), Dynamic Programming, Princeton University Press. Dover paperback edition (2003), ISBN 0486428095.
- Bertsekas, D. P. (2000), Dynamic Programming and Optimal Control (2nd ed.), Athena Scientific, ISBN 1-886529-09-4. In two volumes.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001), Introduction to Algorithms (2nd ed.), MIT Press & McGraw-Hill, ISBN 0-262-03293-7. Especially pp. 323–69.
- Dreyfus, Stuart E.; Law, Averill M. (1977), The art and theory of dynamic programming, Academic Press, ISBN 978-0122218606.
- Giegerich, R.; Meyer, C.; Steffen, P. (2004), "A Discipline of Dynamic Programming over Sequence Data", Science of Computer Programming 51 (3): 215–263, doi:10.1016/j.scico.2003.12.005, http://bibiserv.techfak.uni-bielefeld.de/adp/ps/GIE-MEY-STE-2004.pdf.
- Meyn, Sean (2007), Control Techniques for Complex Networks, Cambridge University Press, ISBN 9780521884419, https://netfiles.uiuc.edu/meyn/www/spm_files/CTCN/CTCN.html.
- S. S. Sritharan, "Dynamic Programming of the Navier-Stokes Equations," in Systems and Control Letters, Vol. 16, No. 4, 1991, pp. 299–307.
- Stokey, Nancy; Lucas, Robert E.; Prescott, Edward (1989), Recursive Methods in Economic Dynamics, Harvard Univ. Press, ISBN 9780674750968.
External links
- An Introduction to Dynamic Programming
- Dyna, a declarative programming language for dynamic programming algorithms
- Wagner, David B., 1995, "Dynamic Programming." An introductory article on dynamic programming in Mathematica.
- Ohio State University: CIS 680: class notes on dynamic programming, by Eitan M. Gurari
- A Tutorial on Dynamic programming
- MIT course on algorithms - Includes a video lecture on DP along with lecture notes
- More DP Notes
- King, Ian, 2002 (1987), "A Simple Introduction to Dynamic Programming in Macroeconomic Models." An introduction to dynamic programming as an important tool in economic theory.
- Dynamic Programming: from novice to advanced A TopCoder.com article by Dumitru on Dynamic Programming
- Algebraic Dynamic Programming - a formalized framework for dynamic programming, including an entry-level course to DP, University of Bielefeld
- Dreyfus, Stuart, "Richard Bellman on the birth of Dynamic Programming."
- Dynamic programming tutorial
- A Gentle Introduction to Dynamic Programming and the Viterbi Algorithm
- Tabled Prolog BProlog and XSB